Here we will consider sampling a normal distribution $n$ mutually independent times, and consider the density function for mean of the sample. That is, let $X$ be a normal random variable with density function $\displaystyle{ Z_{\mu,\sigma} }\,$ , and let $\displaystyle{ X_1 }\, $ , $\,\displaystyle{ X_2 }\, $ , … , $\,\displaystyle{ X_n }$ be $n$ mutually independent samples of $X\;$ . Then
$$ \bar{X} =\textstyle{\frac{1}{n}}\left( X_1 + \cdots + X_n \right) $$
will be the random variable denoting the mean of the sample.
For the purposes of determining the density function of $\bar{X}\,$ , we will first determine its moment generating function.
We already know how to compute the moment generating function for a linear combination of independent random variables. That is, we have seen that if $\displaystyle{ X_1 }\, $ , … , $\,\displaystyle{ X_n }$ are mutually independent, then
$$
M_{a_1\, X_1 +\cdots +a_n\, X_n}(t) =M_{a_1\, X_1}(t) \cdot M_{a_2\, X_2}(t) \cdot \, \cdots\, \cdot M_{a_n\, X_n}(t)
=M_{X_1}(a_1\, t) \cdot M_{X_3}(a_2\, t)\cdot \, \cdots \, \cdot M_{X_n}(a_n\, t) \;\text{.}
$$
Thus
$$
M_{\bar{X}}(t) =M_{\frac{1}{n}X_1}(t)\cdot M_{\frac{1}{n}X_2}(t)\cdot\,\cdots\,\cdot M_{\frac{1}{n}X_n}(t)
=M_{X_1}\left(\frac{t}{n}\right)\cdot M_{X_2}\left(\frac{t}{n}\right)\cdot\,\cdots\,\cdot M_{X_n}
\left(\frac{t}{n}\right) \;\text{.}
$$
Since the random variables $\displaystyle{ X_1 }\, $ , … , $\,\displaystyle{ X_n }$ all share the same density function, this gives
$$ M_{\bar{X}}(t) =M_{X}\left( \frac{t}{n}\right)^n \;\text{.} $$
We have already determined the moment generating function for the normal random variable $X$ with density $\displaystyle{ Z_{\mu,\sigma} }$ to be
$$ M_X(t) ={\rm e}^{\mu\, t +\frac{1}{2}\,\sigma^2\, t^2} \;\text{.} $$
This allows us to say that
$$
M_{\bar{X}}(t) =\left( {\rm e}^{\mu\frac{t}{n} +\frac{1}{2}\,\sigma^2\left(\frac{t}{n}\right)^2 } \right)^n ={\rm e}^{\mu t +\frac{1}{2}\,\left(\frac{\sigma^2}{n}\right)\, t^2 } \;\text{.}
$$
The special thing about this is that the resulting moment generating function looks a lot like that of $\displaystyle{ Z_{\mu,\sigma} }\;$ . In fact, it is precisely the moment generating function of $\displaystyle{ Z_{\mu,\frac{\sigma}{\sqrt{n}}} }\;$ . We have already noted that the moment generating function for a random variable completely determines the probability density function of that random variable. Consequently $\bar{X}$ has density $\displaystyle{ Z_{\mu,\frac{\sigma}{\sqrt{n}}} }\;$ . That is, $\,\bar{X}$ is also a normal random variable, with the same mean as $X\,$ , but a smaller standard deviation – i.e. $\displaystyle{ \frac{\sigma}{\sqrt{n}} }$ rather than $\sigma\;$ .
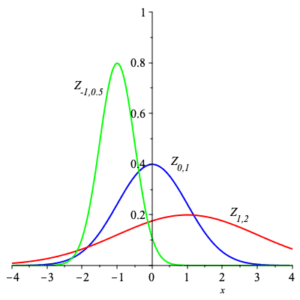
Here are graphs of the density functions for $\displaystyle{ Z_{1,2} }\,$ , $\displaystyle{ Z_{0,1} }\,$ , and $\displaystyle{ Z_{-1,\frac{1}{2}} }\;$ . Notice how the density function with smaller standard deviation has graph much more concentrated about the mean.
The above observation regarding the average of a sample from a normal random variable can be seen as a generalization of an easier fact.
Sum of Independent Normal Random Variables
Fact: Let $\displaystyle{ X_1 }$ and $\displaystyle{ X_2 }$ be two independent random variables, with means $\displaystyle{ \mu_1 }$ and $\displaystyle{ \mu_2 }\,$ , and variances $\displaystyle{ \sigma_1^2 }$ and $\displaystyle{ \sigma_2^2 }\,$ , respectively. Then
$$ X_1 + X_2 $$
is a normal random variable, with mean $\displaystyle{ \mu_1 +\mu_2 }$ and variance $\displaystyle{ \sigma_1^2 +\sigma_2^2 }\;$ .
This can be seen by following the logic above. The moment generating functions for $\displaystyle{ X_1 }$ and $\displaystyle{ X_2 }$ are
$$
M_{X_1} ={\rm e}^{\mu_1 t +\frac{1}{2}\sigma_1^2 t^2} \qquad \text{and} \qquad
M_{X_2} ={\rm e}^{\mu_2 t +\frac{1}{2}\sigma_2^2 t^2} \,\text{,}
$$
respectively. Thus
$$
\begin{array}{rl}
M_{X_1 +X_2} & =M_{X_1} M_{X_2} \\ & \\
& ={\rm e}^{\mu_1 t +\frac{1}{2}\sigma_1^2 t^2} {\rm e}^{\mu_2 t +\frac{1}{2}\sigma_2^2 t^2} \\ & \\
& ={\rm e}^{\left(\mu_1 +\mu_2\right) t +\frac{1}{2} \left(\sigma_1^2 +\sigma_2^2\right) t^2}
\end{array}
$$
is the moment generating function for $\displaystyle{ Z_{\mu_1 +\mu_2 , \sqrt{\sigma_1^2 +\sigma_2^2}} }\;$ . That is, $\displaystyle{ X_1 +X_2 }$ is a normal random variable with mean $\displaystyle{ \mu_1 +\mu_2 }$ and variance $\displaystyle{ \sigma_1^2 +\sigma_2^2 }\;$ .
Here are a couple of computational examples.
Example: A standard normal random variable, $\,X$ (with density $\displaystyle{ Z_{0,1} }\,$ ), takes values in the interval $[-1.96, 1.96]\,$ , symmetric about its mean, with $95\%$ probability. If $\bar{X}$ is the sample mean of twenty-five samples of $X\,$ , find the interval symmetric about its mean within which $\bar{X}$ takes $95\%$ of its values.
Since $X$ and $\bar{X}$ both have the same mean, $\,\displaystyle{ \mu_X =\mu_{\bar{X}} =0 }\,$ , $\,\bar{X}$ has density function $\,\displaystyle{ Z_{0,\frac{1}{\sqrt{25}}} =Z_{0,0.2} }\;$ . This takes $95\%$ of its values in the symmetric interval $\left[ -\frac{1.96}{5}, \frac{1.96}{5} \right] =[-.392, .392]\;$ .
Example: If $X$ is standard normal random variable, how large must a sample be to ensure that $\bar{X}$ takes $95\%$ of its values in $[-.15,.15]\;$ ?
$$ \frac{1.96}{\sqrt{n}} \le .15 \;\text{.} $$
That is,
$$ \frac{1.96}{.15} \le \sqrt{n} \,\text{,} $$
or
$$ \left(\frac{1.96}{.15}\right)^2 =170.74 \le n \;\text{.} $$
That is, we need a sample size of greater than $170$ to ensure that our sample mean will be in $[-.15,.15]$ with probability at least $.95\;$ .
Here are a couple of ways that this might be used.
Example: Experience has shown that the melting point of a certain plastic is described by a normal distribution with mean $85C$ and standard deviation $4C\;$ . Twenty samples from a new production process are tested and found to have an average melting point of $82.2C\;$ . What is the probability that a sample of this size from the original process will have average melting point less than $82.5C\;$ ? Does the new process yield product as stable as the original process temperatures near to $80C\;$ ?
We note that
$$
\begin{array}{rl}
P\left( X_{85,\frac{4}{\sqrt{20}}} \lt 82.5\right) & =P\left(X_{0,\frac{2}{\sqrt{5}}} \lt -2.5\right) \\ & \\
& =P\left( X_{0,1} \lt -2.5\cdot \frac{2}{\sqrt{5}} \right) \\ & \\
& =0.013 \;\text{.}
\end{array}
$$
That is, there is less than a $1.5\%$ chance that a sample of the same size would exhibit such a low average melting point.
A reasonable conclusion is that the new process does not yield a plastic which is as stable as the old, at least when temperatures get above $80C\;$ .
Example: In the preceding example, the mean melting point of plastics produced by the new process needs to be determined to within $.1C$ with $99\%$ accuracy. Assuming that the standard deviation for the new process is $4C\,$ , just as for the old process, how large of a sample is needed to obtain such accuracy?
We address the following mathematical question: for how large of an $n$ will $\bar{X}$ take $99\%$ of its values in $\left[ \mu -.1, \mu +.1 \right]\;$ ? Since $\bar{X}$ has density $\displaystyle{ Z_{\mu,\frac{4}{\sqrt{n}}} }\,$ , this is asking how large to make $n$ so that
$$ P\left( \mu -.1 \lt Z_{\mu,\frac{4}{\sqrt{n}}} \lt \mu +.1 \right) \ge .99 \;\text{.} $$
That is,
$$ P\left( -.1 \lt Z_{0,\frac{4}{\sqrt{n}}} \lt .1 \right) \ge .99 \,\text{,} $$
or
$$ P\left( -\frac{\sqrt{n}}{40} \lt Z_{0,1} \lt \frac{\sqrt{n}}{40} \right) \ge .99 \;\text{.} $$
Since $ P\left( -2.58 \lt Z_{0,1} \lt 2.58 \right) \ge .99 \,$ , we need
$$ \frac{\sqrt{n}}{40} \ge 2.58 \,\text{,} $$
or
$$ n\ge ( 40\cdot 2.58)^2 =10650.24 \;\text{.} $$
Thus we need a sample size of greater than $10650$ to ensure that our sample mean will be within $.1C$ of its actual mean.
These examples should be compared with those encountered when we looked at Chebyshev’s theorem. In both cases, more control over the standard deviation of a probability density gives us tighter spread about the mean.