Many phenomena have a probability when we consider one sample space, but we wish to consider another, more restricted, sample space. For example, suppose we know that the incidence of left-handedness among all people is 10.3%, but we wish to examine the incidence of left-handedness among women. This is a restriction (from all people to just women) of the set in which we are considering the phenomenon of left-handedness. Such a restriction is called a condition. The probability of an outcome, given a condition, is called a conditional probability.
Just as we write $P(X)$ for the probability of event $X$ when the probability space is understood, so too we will write
$$ P(X\big|C) $$
for the conditional probability of event $X\,$ , subject to condition $C\,$ , to indicate that the probability space has been changed by the condition. Thus we might write $P(L\big|W)$ for the probability that a person will be a lefty given that the person is a woman. We would just have to make clear that $L$ refers to left-handedness, and $W$ refers to women.
Example: Cards
What is the probability of being dealt a face card from a deck of cards, given that one card – $Q\heartsuit$ – has already been dealt? If the previously dealt card is $4\spadesuit$?
In the first case, we consider the experiment of two cards being dealt. Let $\displaystyle{ C_1 }$ denote the first card and $\displaystyle{ C_2 }$ the second. We seek $\displaystyle{ P\left( C_2=\text{face card} \big| C_1=Q\heartsuit\right) }\;$ . Since the condition implies that $\displaystyle{ C_2 }$ is picked from fifty-one cards, of which eleven are face cards, the probability is
$$ P\left( C_2=\text{face card} \big| C_1=Q\heartsuit\right) = \frac{11}{51} \;\text{.} $$
In the second case, we consider the same experiment as above. But we seek $\displaystyle{ P\left( C_2=\text{face card} \big| C_1=4\spadesuit\right) }$ Since the condition implies that $\displaystyle{ C_2 }$ is picked from fifty-one cards, of which twelve are face cards, the probability is
$$ P\left( C_2=\text{face card} \big| C_1=4\spadesuit\right) = \frac{12}{51} \;\text{.} $$
Example: Roll of a Die
What is the probability the second roll of a die is $5\,$ , given that the first roll is $3\;$ ? How about if the first roll is $2\;$ ?
In the first case, we consider the experiment of rolling a die twice. There are thirty-six possible outcomes for this experiment. We let $\displaystyle{ R_1 }$ denote the result of the first roll, and $\displaystyle{ R_2 }$ the result of the second. We seek $\displaystyle{ P\left( R_2=5 \big| R_1=3 \right) }\;$ . Since there are six possible equally likely outcomes on the second roll, given that that the first roll was $3\,$ , the probability is
$$ P\left( R_2=5 \big| R_1=3\right) = \frac{1}{6} \;\text{.} $$
The second case plays out the same way. We have
$$ P\left( R_2=5 \big| R_1=2\right) = \frac{1}{6} \;\text{.} $$
In settings where probability is determined by counting, conditional probability is computed by
$$ P(X\big|C) = \frac{\#(X\cap C)}{\#(C)} \,\text{,} $$
while if more subtle methods are needed to determine probabilities, the computation is
$$ P(X\big|C) = \frac{P(X\cap C)}{P(C)} \;\text{.} $$
These can be taken as definitions.
Example: Determine Conditional Probabilities
A box contains twenty balls. Three are yellow, seven are red, and ten are blue. Of these balls, two of the yellow balls have a black equatorial stripe, two of the red balls do as well, and only one of the blue balls does. The diagram below illustrates this.
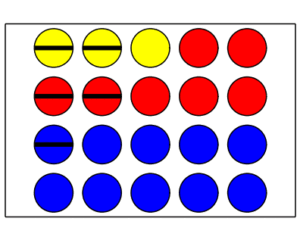
balls in a box
One ball is pulled at random from the box. The probability of it having a stripe is
$$ \frac{5}{20} =\frac{1}{4} $$
as there are five striped balls among the twenty balls. If we are given the further information that a yellow ball has been pulled, this changes the calculation. Since there are two striped balls among the three yellow balls, the probability of having pulled a striped ball under the given constraint is
$$ \frac{2\text{ striped yellows}}{3 \text{ yellows}} =\frac{2}{3} \;\text{.} $$
Similarly, if we are instead given the information that a red ball has been pulled the probability of its being striped is
$$ \frac{2\text{ striped reds}}{7 \text{ reds}} =\frac{2}{7} \;\text{.} $$
And if we are instead given the information that a blue ball has been pulled the probability of its being striped is
$$ \frac{1\text{ striped blue}}{10 \text{ blues}} =\frac{1}{10} \;\text{.} $$
The above definition
$$ P(X\big|C) = \frac{P(X\cap C)}{P(C)} $$
can be rewritten as
$$ P(X\cap C) =P(C)\cdot P(X\big|C) \;\text{.} $$
This is known as the fundamental multiplication rule for probabilities.
Example: Using the Multiplication Rule
Here we will determine the probability of getting two green balls on drawing two balls from a box containing four red, two black and three green balls (shown below). We will assume that the first ball drawn is not returned to the box before the second is drawn.
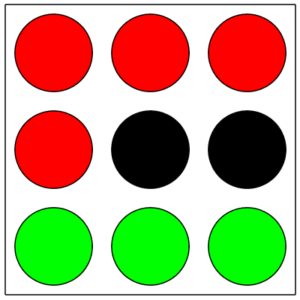
nine balls in a box
Letting $\displaystyle{ X_1 }$ denote the event of drawing a green ball on the first draw, and $\displaystyle{ X_2 }$ the event of drawing a green on the second draw. In order to use the counting principle, we need the probabilities for each particular drawing possibility to be identical ( $\,\frac{1}{9}$ as there are nine balls), we will label the balls $\displaystyle{ r_1 }\,$ , $\,\displaystyle{ r_2 }\,$ , $\,\cdots\,$ , $\,\displaystyle{ b_1 }\,$ , $\,\cdots\,$ , $\displaystyle{ g_3 }\;$ . We have that the number of ways to draw a green ball on the first draw is $\displaystyle{ P\left( X_1 \right) }$ $=\frac{3}{9} =\frac{1}{3} \;$ . The event whose probability we wish to determine is $\displaystyle{ P\left( X_1 \cap X_2 \right) }\;$ .
We will use the multiplication rule to determine $\displaystyle{ P\left( X_1 \cap X_2 \right) =P\left( X_2\big| X_1 \right)\cdot P\left( X_1 \right) }$ by determining $\displaystyle{ P\left( X_2\big| X_1 \right) }\;$ . To this end, if $\displaystyle{ X_1 }$ holds, then on the first draw we have taken one of $\displaystyle{ g_1 }\,$ , $\,\displaystyle{ g_2 }\,$ , or $\displaystyle{ g_3 }\,$ , and in any case there are exactly two green balls left among the remaining eight balls. Thus
$$ P\left( X_2\big| X_1 \right) =\frac{2}{8} =\frac{1}{4} \,\text{,} $$
and
$$
P\left( X_1 \cap X_2 \right) =P\left( X_2\big| X_1 \right)\cdot P\left( X_1 \right)
=\frac{1}{4}\cdot\frac{1}{3} =\frac{1}{12} \;\text{.}
$$
The advantage of using the multiplication rule should become apparent if one tries to compute the desired by a brute force counting of all possible outcomes of this two-step process. In what follows, a diagram of the sample space for the process is illustrated, with each possible outcome indicated by an “x”. We have shaded the event $\displaystyle{ X_1 }$ yellow, and the event $\displaystyle{ X_2 }$ blue. Thus the number of possible outcomes is $72$ and the number of ways to get two greens is $6\;$ . The advantage of using the multiplication rule is that it reduces the computation of probability to the multiplication of a sequence of probabilities computed for one-step processes. Henceforth, in calculating probabilities, such techniques will almost always be used to avoid time-consuming counting in the entire sample space.
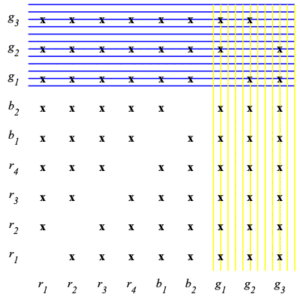
explicit counting – getting two green balls
Example: The Multiplication Rule – Replacement Versus Non-replacement
Here we repeat two versions of the experiment drawing two cards from a standard deck. In the first, we draw a card, return it to the deck, shuffle, and draw a card. In the second, we draw a card, do not return it to the deck, and then draw a second. In the first version, we say that the experiment is performed with replacement, so that the conditions of the experiment are returned to original before a second card is drawn. The second version is said to be performed without replacement.
In both cases, we wish to understand what the probability of drawing a queen for the second card, given that the first card is a face-card.
Replacement
Here the second draw is from a full standard deck. Thus the probability that we draw a queen is $\frac{4}{52} =\frac{1}{13}\; $ . This is because there are four queens in a standard deck.
Non-replacement
This is a bit more complicated, and we will use the multiplication rule. We will consider two different possibilities. The first is that the first card chosen was not a queen. Now there are fifty-one cards and four queens available, so the probability of drawing a queen is $\frac{4}{51}\; $ . The second is that the first card chosen was a queen. Now there are fifty-one cards and three queens available, so the probability of drawing a queen is $\frac{3}{51}\; $ . Denoting by $\displaystyle{ Q_2 }$ the event of getting a queen on the second draw, by $\displaystyle{ Q_1^c \cap F_1 }$ the event of getting a face-card but not a queen on the first draw, and by $\displaystyle{ Q_1 }$ the event of getting a queen on the first draw (so that $\displaystyle{ Q_2\subset F_1 }\, $ ), we have that
$$
\begin{array}{rl}
P\left( Q_2 \,\big|\, F_1\right) & =\frac{ P\left( Q_2 \cap F_1\right) }{ P\left( F_1\right) } \\ & \\
& =\frac{ P\left( Q_2 \cap \left( F_1\cap Q_1^c\right)\right) +P\left( Q_2 \cap Q_1\right) }
{ P\left( F_1\right) } \\ & \\
& =\frac{ P\left( Q_2 \,\big|\, \left( F_1\cap Q_1^c\right)\right)\cdot P\left( F_1\cap Q_1^c\right)
+P\left( Q_2 \,\big|\, Q_1\right)\cdot P\left( Q_1\right) }{ P\left( F_1\right) } \\ & \\
& =\frac{\frac{4}{51}\cdot\frac{8}{52} +\frac{3}{51}\cdot\frac{4}{52}}{\frac{12}{52}} \\ & \\
& =\textstyle{\frac{11}{153}} \;\text{.}
\end{array}
$$
Comparing this with $\frac{1}{13}$ from the replacement case, we see that knowing that the first card was a face card reduces the likelihood that the second card will be a queen: $\, \frac{11}{153} \lt\frac{1}{13}\; $ .
When considering conditions and probability, often times one condition is easily understood but the reverse condition is important. As an easy example, consider the above example determining conditional probabilities of pulling a striped ball from a box. If instead we know that we pulled a striped ball from the box, what is the probability that the ball is yellow? red? blue? A more important example might be in genetic testing. Suppose that $93\%$ of people who develop a syndrome carry a specific genetic marker, and $12\%$ of people who do not develop the syndrome carry the genetic marker. A test is developed for the genetic marker as a way to screen for the syndrome. If a boy tests positive for the genetic marker, can we say how likely he is to develop the syndrome? This is an example in that we are given information regarding the conditional probabilities for the marker given (or not) the syndrome, and we ask for a conditional probability for the syndrome given the marker. It is easy to see how this latter example might be important.
There is a way to reverse a condition, and with it we will be able to address the question regarding the syndrome test above – we will be able to say how likely one is to develop the syndrome.
Bayes’ Theorem
Suppose we know $\displaystyle{ P\left( B \big| A \right) }\,$ , $\, P(A)\, $ , $\displaystyle{ P\left( B \big| A^c \right) }\,$ , and $\displaystyle{ P\left( A^c \right) }\;$ . With this information, we can determine and $\displaystyle{ P\left( A \big| B \right) }\;$ . That is, we can reverse our conditional probability. In fact
$$
P\left( A \big| B \right) =\frac{P\left( B \big| A \right) \cdot P(A)}
{P\left( B \big| A \right) \cdot P(A) +P\left( B \big| A^c \right) \cdot P(A^c)} \;\text{.}
$$
Proof
To see this, we use the multiplication rule. Note that
$$ P(B \cap A) =P\left( B \big| A \right)\cdot P(A) $$
and
$$ P\left( B \cap A^c\right) =P\left( B \big| A^c \right)\cdot P\left( A^c\right) \;\text{.} $$
That is, our part of known information allows us to determine how likely $B$ and $A$ are to simultaneously hold (i.e. $P(B \cap A)\, $ ). Another part of our known information allows us to determine how likely $B$ and $\displaystyle{ A^c }$ are to simultaneously hold (i.e. $\displaystyle{ P\left(B \cap A^c\right) }\, $ ). Together these allow us to determine how likely $B$ itself is to hold. Since
$$
B =(B\cap A) \cup \left( B\cap A^c\right) \;\text{ and }\; (B\cap A) \cap \left( B\cap A^c\right) =\emptyset \,\text{,}
$$
we have
$$
P(B) =P( B\cap A) +P\left( B \cap A^c \right) \;\text{.}
$$
This is illustrated in the following diagram.
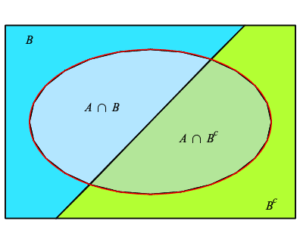
balls in a box
Since
$$ P\left( A\big| B \right) =\frac{P(A\cap B)}{P(B)} =\frac{P(A\cap B)}{P( B\cap A) +P\left( B \cap A^c \right)} $$
and we have expressions for the numerator and denominator of this right-hand side, we have
$$
P\left( A\big| B \right) =\frac{P\left( B \big| A \right) \cdot P(A)}
{P\left( B \big| A \right) \cdot P(A) +P\left( B \big| A^c \right) \cdot P(A^c)} \;\text{.}
$$
One can generalize this theorem to the case when a collection of mutually exclusive conditions $\displaystyle{ A_1 }\, $ , $\, \displaystyle{ A_2 }\, $ , … , $\,\displaystyle{ A_n }$ exhaust the sample space (i.e. the space of possible outcomes). In this case, if we know pairs $\displaystyle{ \left( P\left( B\big| A_1\right) , P\left( A_1 \right) \right) }\, $ , $\, \displaystyle{ \left( P\left( B\big| A_2\right) , P\left( A_2 \right) \right) }\, $ , … , $\,\displaystyle{ \left( P\left( B\big| A_n\right) , P\left( A_n \right) \right) }\,$ , we have
$$
P\left( A_1\big| B \right) =\frac{P\left( B \big| A_1 \right) \cdot P\left(A_1\right)}
{P\left( B \big| A_1 \right) \cdot P\left(A_1\right) +P\left( B \big| A_2 \right) \cdot P\left(A_2\right)
+\cdots +P\left( B \big| A_n \right) \cdot P\left(A_n\right)} \;\text{.}
$$
The data in the discussion of Bayes’ theorem above is often presented in a table:
$$
\begin{array}{c|c|c|}
& A & A^c \\ \hline B & P\left(B\,\big| \, A\right) & P\left(B\,\big| \, A^c\right) \\ \hline
B^c & P\left(B^c \,\big| \, A\right) & P\left(B^c \,\big| \, A^c\right) \\ \hline
\end{array}
$$
This table has the feature that each column sums to $1\;$ . Of course such a table is more complicated if the sample space is split into more than simply one set and its complement – as suggested by the preceding generalization.
Here is how to use Bayes’ theorem to address the questions above:
-
If instead we know that we pulled a striped ball from the box, what is the probability that the
ball is yellow? red? blue? - Can we say how likely one is to develop the syndrome?
Example: Determine Conditional Probabilities (continued)
If a striped ball is drawn from the box in our example above, what is the probability that it is yellow? Given the notation
$$
S = \text{ striped } , Y = \text{ yellow } , R = \text{ red } , B = \text{ blue } ,
$$
we have
$$
\begin{array}{rl}
\left( P\left( S\big| Y\right) , P(Y) \right) & =\left( \frac{2}{3} , \frac{3}{20} \right) \\
\left( P\left( S\big| R\right) , P(R) \right) & =\left( \frac{2}{7} , \frac{7}{20} \right) \quad\text{and} \\
\left( P\left( S\big| B\right) , P(B) \right) & =\left( \frac{1}{10} , \frac{10}{20} \right) \;\text{.}
\end{array}
$$
Since conditions $Y\,$ , $\, R\,$ , and $B$ are exhaustive and mutually exclusive, according to Bayes’ theorem we have
$$
P\left( Y\big| S \right) =\frac{P\left( S \big| Y \right) \cdot P(Y)}
{P\left( S \big| Y \right) \cdot P(Y) +P\left( S \big| R \right) \cdot P(R) +P\left( S \big| B \right) \cdot P(B)}
= \frac{P\left( \frac{2}{3} \right) \cdot P\left( \frac{3}{20} \right)}{P\left( \frac{2}{3} \right) \cdot P\left( \frac{3}{20} \right)
+P\left( \frac{2}{7} \right) \cdot P\left( \frac{7}{20} \right) +P\left( \frac{1}{10} \right) \cdot P\left( \frac{10}{20} \right)}
=\frac{2}{5} \;\text{.}
$$
This could have been determined, of course, by simply counting the striped balls and checking how many of them are yellow. But the technique outlined above is broadly useful in settings where counting is unfeasible.
Example: Can We Determine Conditional Probability of Developing Syndrome?
Recall the problem. Suppose that $93\%$ of people who develop a syndrome carry a specific genetic marker, and $12\%$ of people who do not develop the syndrome carry the genetic marker. A test is developed for the genetic marker as a way to screen for the syndrome. If a boy tests positive for the genetic marker, can we say how likely he is to develop the syndrome?
Letting $S$ denote a person developing the syndrome (and $\displaystyle{ S^c }$ denote a person not developing the syndrome). Also, let $T$ denote a person testing positive for the genetic marker (and similarly $\displaystyle{ T^c }$ denote testing negative. The data given are the conditional probabilities $\displaystyle{ P\left(T\big| S\right) }$ and $\displaystyle{ P\left(T\big| S^c\right) }\;$ . Thus we have the following conditional probability table:
$$
\begin{array}{c|c|c}
& P(S)= \text{ ?} & P\left(S^c\right)= \text{ ?} \\ \hline T & .93 & .12 \\ \hline T^c & .07 & .88
\end{array} \;\text{.}
$$
Bayes’ theorem tells us that in order to reverse the conditional, we need to know the likelihood of $S$ occurring (and so also of $\displaystyle{ S^c }\,$ ). So as it stands, we do not have enough information to determine the conditional probability $\displaystyle{ P\left( S\big| T\right) }\;$ . But if we know by some method that $4\%$ of the population will develop the syndrome (so that $P(S) =.04$ and $\displaystyle{ P\left(S^c\right) =1-.04 =.96 }\,$ ), we can complete the task at hand:
$$
P\left( S\big| T \right) =\frac{P\left( T \big| S \right) \cdot P(S)}
{P\left( T \big| S \right) \cdot P(S) +P\left( T \big| S^c \right) \cdot P\left(S^c\right)}
= \frac{.93 \cdot .04}{.93 \cdot .04 +.12 \cdot .96} =.244 \;\text{.}
$$
We see that even though one tested positive for the genetic marker, and there is a high probability of testing positive if the syndrome is to develop, there is still a fairly low probability ( $\, \lt 25\%\,$ ) that having tested positive one actually develops the syndrome. The reason is that most (over $75\%\,$ ) of those testing positive are false positives – that is they test positive despite not eventually developing the syndrome.
One can easily see how this might be of importance to someone being examined for a potentially life-threatening disease like AIDS or a degenerative disease like Alzheimer’s. Testing positive for a marker cannot be properly interpreted without complete information.
Note that in the second example above the probability that the second roll is a $5$ has nothing to do with the result of the first roll. Letting $R$ denote the event of a roll of a die, then in the above example we had
$$ P(R=5) =P\left( R_2=5 \big| R_1=3\right) $$
and
$$ P(R=6) =P\left( R_2=6 \big| R_1=1\right) \;\text{.} $$
We call such events independent.
Independence
In the case where the probability of an event is the same whether or not a certain condition is imposed, we say that the event is independent of the condition. Thus, given the discussion above, we would say that the event of rolling a die to get $5$ is independent of having rolled it earlier and got a $3\;$ .
Given our computational definition above, we will say that event $X$ is independent of condition $C$ precisely when
$$ P(X\big| C) = \frac{P(X\cap C)}{P(C)} = P(X) \,\text{,} $$
or
$$ P(X)\cdot P(C) =P(X\cap C) \;\text{.} $$
We can take either of these as our definition of independence.
Example: Flip a Fair Coin Twice
The sample space for two flips of a fair coin is $S =\{ HH, HT, TH, TT\} \, $ , with each possibility having probability $\frac{1}{4}\; $ . If we represent this instead as
$$
\begin{array}{c|cc}
& H_1 & T_1 \\ \hline H_2 & \textstyle{\frac{1}{4}} & \textstyle{\frac{1}{4}} \\ T_2 & \textstyle{\frac{1}{4}} & \textstyle{\frac{1}{4}}
\end{array} \,\text{,}
$$
so that the first row represents the possible outcomes of the first flip, and the first column represents the possible outcomes of the second flip. Note that the probability of getting heads on the second flip is exactly the same as the probability of getting heads on the second flip no matter what we get on the first flip. That is,
$$ P\left( H_2 \right) = P\left( H_2 \,\big| \, H_1 \right) = P\left( H_2 \,\big| \, T_1 \right) = \textstyle{\frac{1}{2}} \;\text{.} $$
The same can be said for the probability of getting a tails on the second flip – it is independent of the first flip. One can also check that the outcome of the first flip is independent of the second flip.
One way to understand this is to say that the coin has no memory. There is no influence on the second flip from any result of the first flip.
We saw an example of this sort of phenomenon above when discussing replacement versus non-replacement. When drawing two cards with replacement from a standard deck, the second choice is independent from the first. We now explore this a bit further.
Example: Drawing Two Cards
Suppose we have a game (like black-jack) where two cards are drawn, without replacement, from a standard deck. It is easy to see that the result of the second draw depends on the result of the first draw. We saw above that the probability of drawing a queen on the second draw, when we know that the first card drawn was a face-card, is $\frac{11}{153}\; $ . One can extend the above discussion to show that the probability of drawing a queen on the second draw (without knowing that the first card was a face-card) is $\frac{1}{13}\; $ . This is a good classroom discussion point, and tells us that without knowing anything about the first draw, the second draw is unaffected.
However, if we play this game twice – that is, draw two cards without replacement, then replace the two cards, shuffle and again draw two cards without replacement – the second time we play the game will be independent of the first. Gambling establishments use this when designing games and determining payouts. Gamblers, on the other hand, often fall for what is commonly called “the gambler’s fallacy” when they raise their bet during a losing streak under the mistaken belief that the streak is bound to turn around.
This is a bit much to illustrate here is full. Instead, what we will show is that the game where two cards are chosen from four without replacement, when repeated (now with replacement), has the feature discussed: the second playing of the game is independent from the first.
We let the four cards be denoted by $A\,$ , $\, B\,$ , $\, C\,$ , and $D\;$ . The table below shows the probabilities for the possible ways to draw two cards without replacement, return the two cards, shuffle, and again draw two cards. The first row gives the twelve possible ways to draw two cards without replacement for the first playing of the game (hence the subscript “1”. The first column gives the twelve possible ways for the second playing of the game.
$$
\begin{array}{c|cccccccccccc}
& AB_1 & AC_1 & AD_1 & BA_1 & BC_1 & BD_1 & CA_1 & CB_1 & CD_1 & DA_1 & DB_1 & DC_1 \\ \hline
AB_2 & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} \\
AC_2 & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} \\
AD_2 & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} \\
BA_2 & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} \\
BC_2 & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} \\
BD_2 & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} \\
CA_2 & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} \\
CB_2 & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} \\
CD_2 & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} \\
DA_2 & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} \\
DB_2 & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} \\
DC_2 & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} &
\textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}} & \textstyle{\frac{1}{144}}
\end{array}
$$
One can check that the probability of getting any specific result on the second game does not depend in any way on a result of the first game. For example, the probability that the first card in the second game is $C$ is (using $X$ and $Y$ as place-holders)
$$ P\left( CX_2 \right) =3\cdot 12\cdot \textstyle{\frac{1}{144}} =\textstyle{\frac{1}{4}} \;\text{.} $$
If we impose the condition that the first game ended with $B\,$ , the computation becomes
$$
P\left( CX_2 \,\big|\, YB_1 \right) =\frac{P\left( CX_2 \cap YB_1 \right)}{P\left( YB_1 \right)}
=\frac{\frac{9}{144}}{\frac{36}{144}} =\textstyle{\frac{1}{4}} \;\text{.}
$$